
R-ggplot2包的介绍与学习(三)
折线图可以反映某种现象的趋势。通常折线图的横坐标是时间变量,纵坐标则是一般的数值型变量。当然,折线图也允许横纵坐标为离散型和数值型。
折线图通常用来对两个连续变量之间的相互依存关系进行可视化。其中x也可以是因子型变量。
善于发现的你,可能会注意到上面三段代码有一个重要的不同之处,那就是第一段和第二段代码中含有group = 1的设置。这样做是因为横坐标的属性设置为了因子,即将连续型的年份和离散型的字符转换为因子,如果不添加group = 1这样的条件,绘图将会报错。故务必需要记住这里的易犯错误的点!
往折线图中添加标记(点) 当数据点密度比较小或采集分布(间隔)不均匀时,为折线图做上标记将会产生非常好的效果。处理的方法非常简单,只需在折线图的基础上再加上geom_point()函数即可。

从图中就可以非常明显的看出,刚开始采集的点分布非常散,而后面采集的点就比较密集,这也有助于对图的理解和应用。
二、绘制多条折线图 上面绘制的都是单条这折线图,对于两个或两个以上的折线图该如何绘制呢?也很简单,只需将其他离散变量赋给诸如colour(线条颜色)和linetype(线条形状)的属性即可,具体参见下文例子。


同样需要注意的是,在绘制多条折线图时,如果横坐标为因子,必须还得加上group=分组变量的参数,否则报错或绘制出错误的图形。
以上绘制的折线图,均采用默认格式,不论是颜色、形状、大小还是透明度,均没有给出自定义的格式。其实ggplot2包也是允许用户根据自己的想法设置这些属性的。

虽然这幅图画的优点夸张,目的是想说明可以通过自定义的方式,想怎么改就可以怎么改。前提是aes()属性的内容与自定义的内容对应上。
绘制堆叠的面积图只需要geom_area()函数再加上一个离散变量映射到fill就可以轻松实现,先忙咱小试牛刀一下。

一幅堆叠的面积图就轻松绘制成功,但我们发现,堆叠的顺序与图例的顺序恰好相反,不用急,只需要加一句命令即可:


其中,colour设置面积图边框的颜色;size设置边框线的粗细;alpha设置面积图和边框线的透明度。

该方法是通过添加堆叠线条(必须设置geom_line()中position参数为stack,否则只是添加了两条线,无法与面积图的顶部重合)。这两幅图的区别在于第二种方式没有绘制面积图左右边框和底边框。在实际应用中,建议不要在面积图中绘制边框线,因为边框的存在可能产生误导。

但通过这种方式(设置面积图的positon=fill)存在一点点小缺陷,即无法绘制出百分比堆积面积图顶部的线条,该如何实现呢?这里只需要对原始数据集做一步汇总工作,让后按部就班的绘制面积图即可。

散点图通常用来刻画两个连续型变量之间的关系,数据集中的每一条观测都由散点图中的一个点来表示。在散点图中也可以加入一些直线或曲线,用来表示基于统计模型的拟合。当数据集记录很多时,散点图可能会彼此重叠,这种情况往往需要一些预处理操作。
散点图可以用来描述两个连续变量之间的关系,一般在做数据探索分析时会使用到,通过散点图发现变量之间的相关性强度、是否线性关系等。

可以使用shape和size分别指定点型和点的大小,如果点型包括填充和描边的话,可用fill和color分别指定填充色和描边色。
可将分组变量(因子或字符变量)赋值给颜色或形状属性,实现分组散点图的绘制

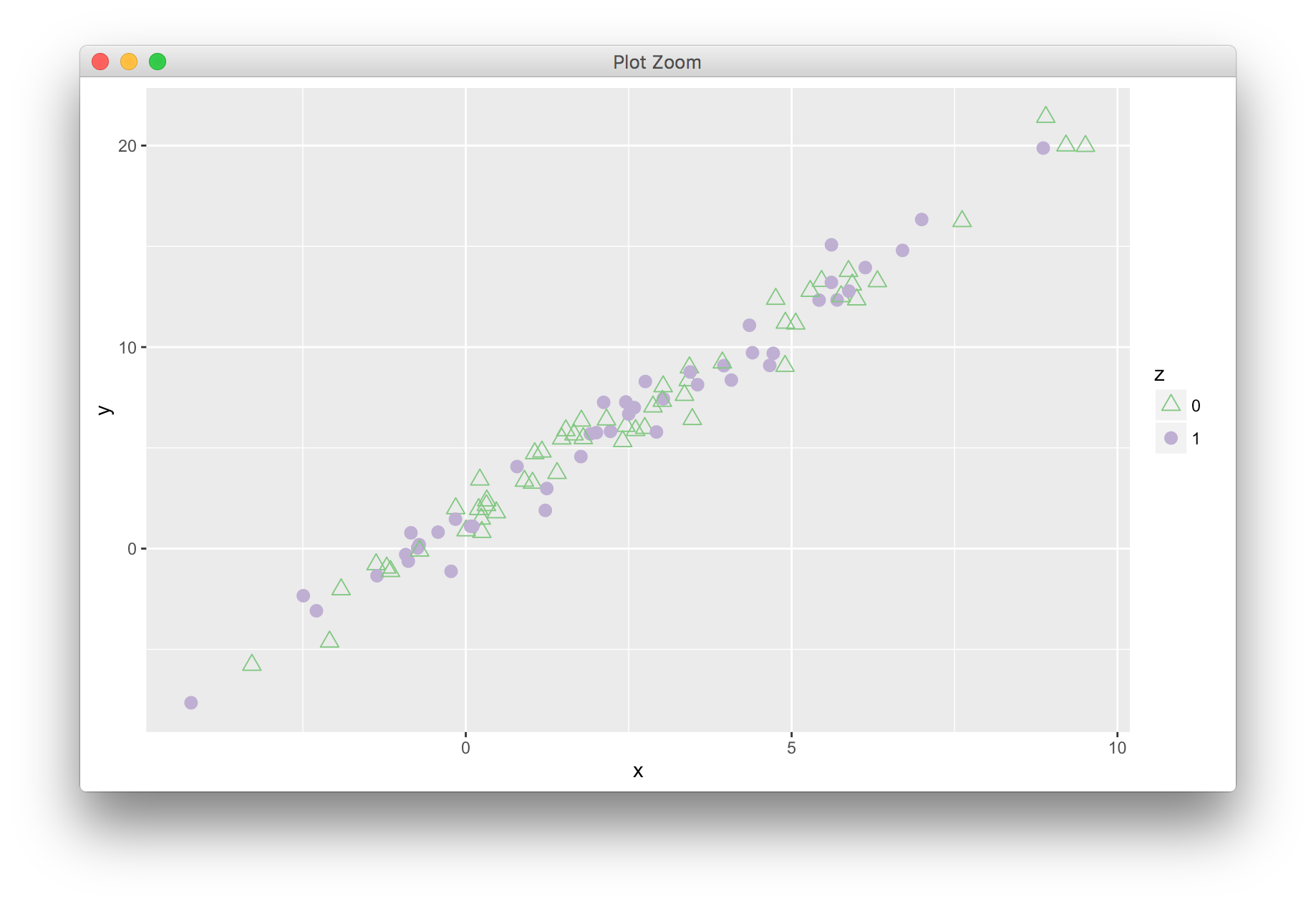
注意点的形状,21-25之间的点的形状,既可以赋值边框颜色,又可以赋值填充色。
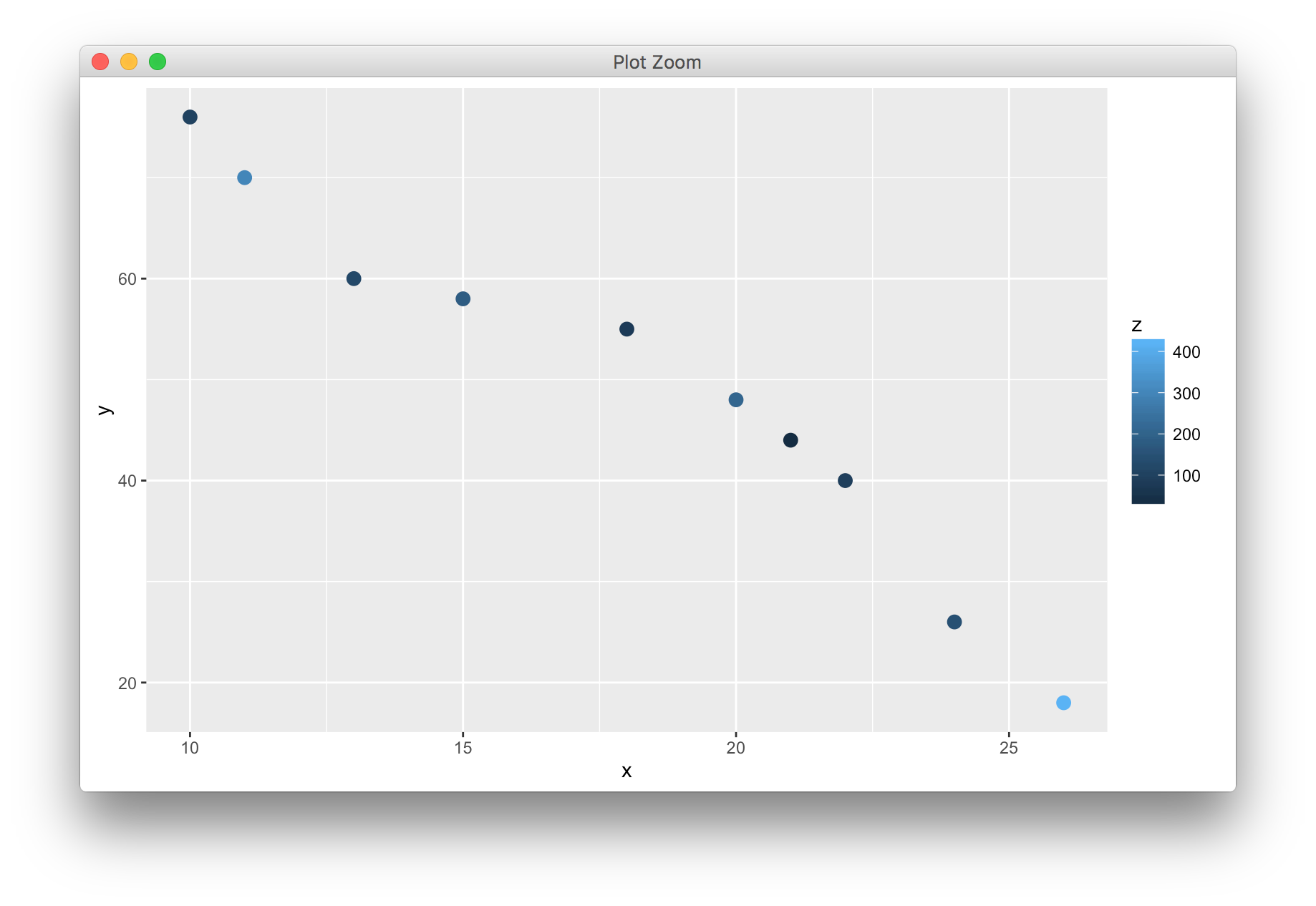
图例上,颜色越深而对应的值越小,如何将值的大小与颜色的深浅保持一致?只需要人为的设置色阶,从低到高设置不同的颜色即可
当然,还可以将连续型变量映射到散点的颜色或大小等存在渐变的属性上,从而呈现三个连续型变量之间的关系。其中人眼对于x轴和y轴所对应变量的变化更为敏感,而对颜色和大小的变化则不那么敏感。

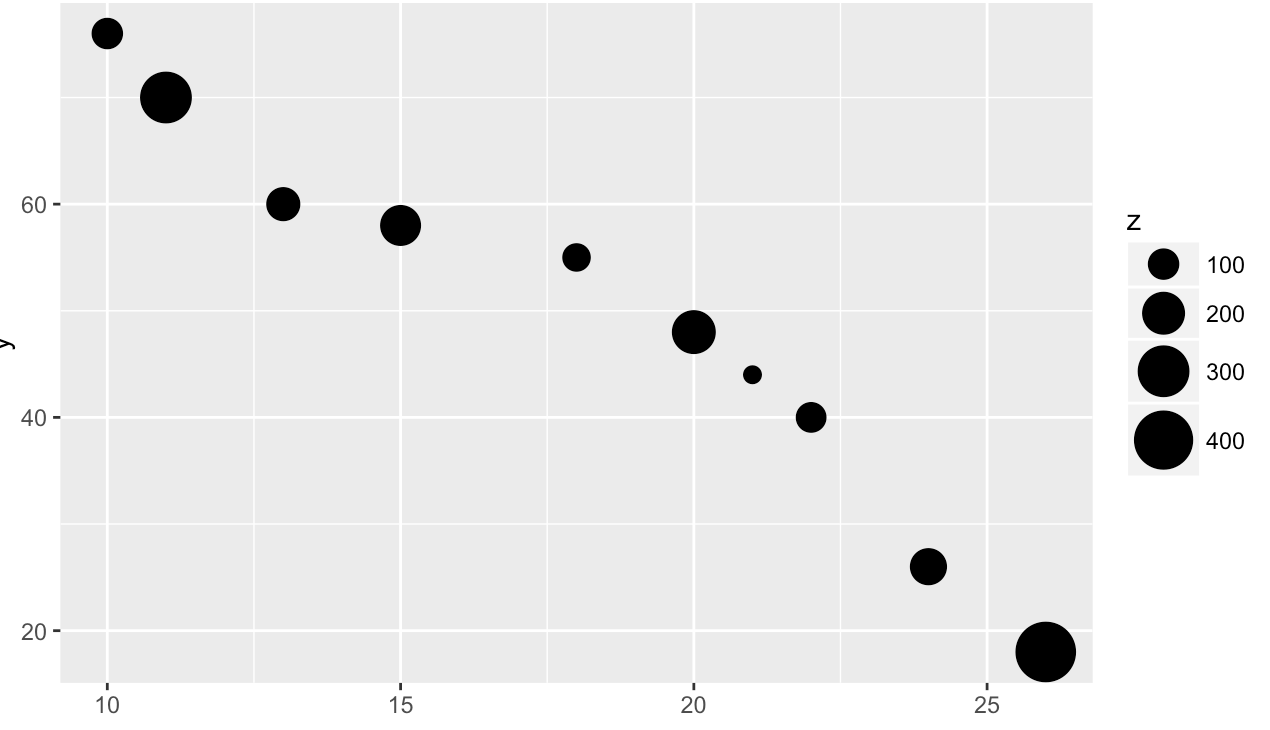
同时映射类别型变量和连续型变量,并设置散点的面积正比于连续型变量的大小,默认为非线性映射。

# 将连续型变量赋给颜色属性或大小属性,自定义双色梯度,色阶间隔顺序由低到高
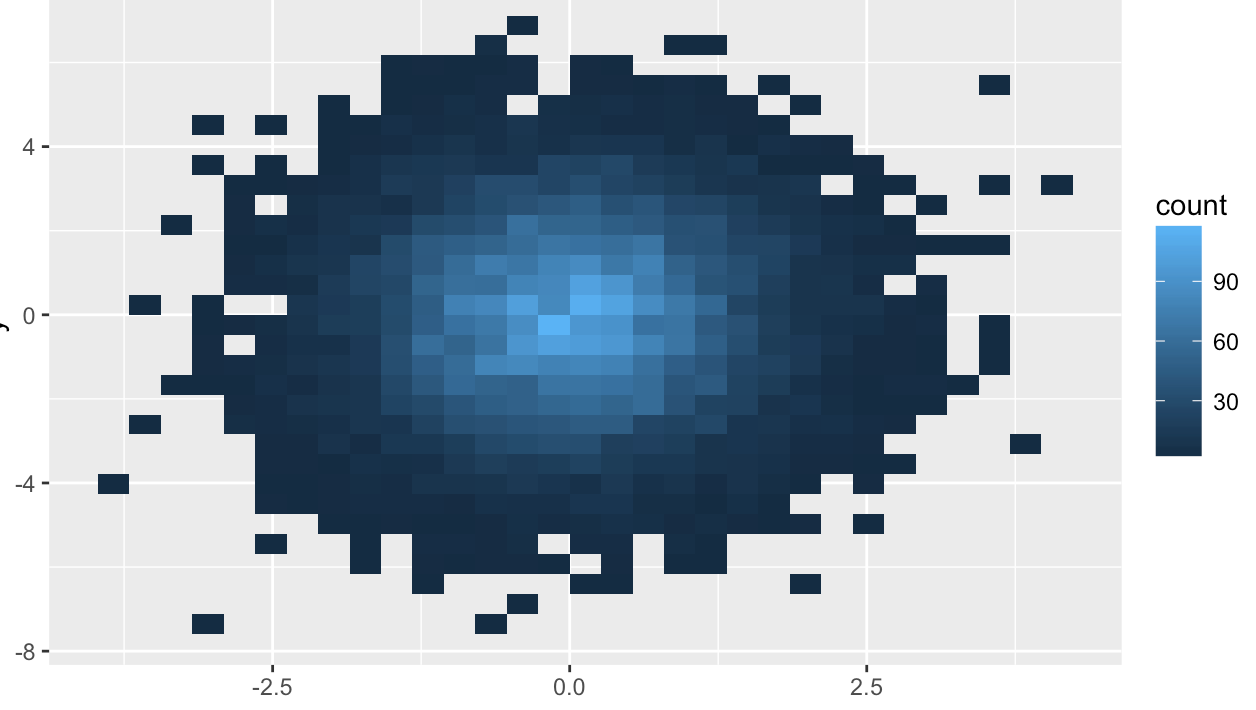
默认情况下,stat_bin2d()函数将x轴和y轴的数据点各分位30段,即参数900个箱子;用户还可以自定义分段个数,以及箱子在垂直和水平方向上的宽度。
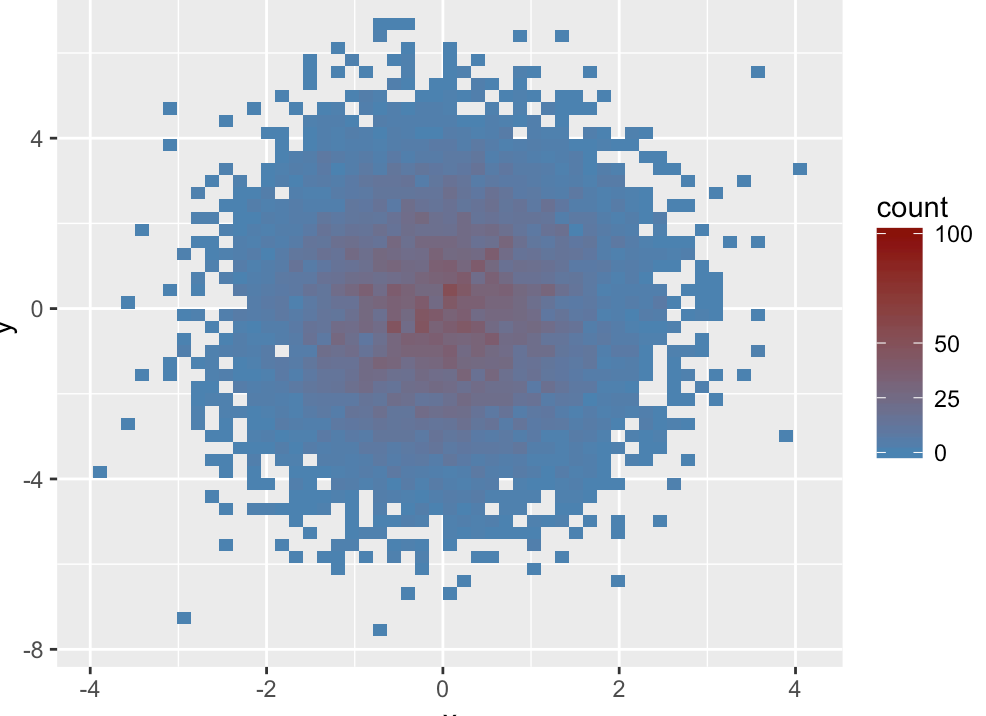
分箱的具体做法是,将点分箱,并统计每个箱中点的个数,然后通过某种方法可视化这个数量。

# 使用stat_density2d作二维密度估计,并将等高线添加到散点图中
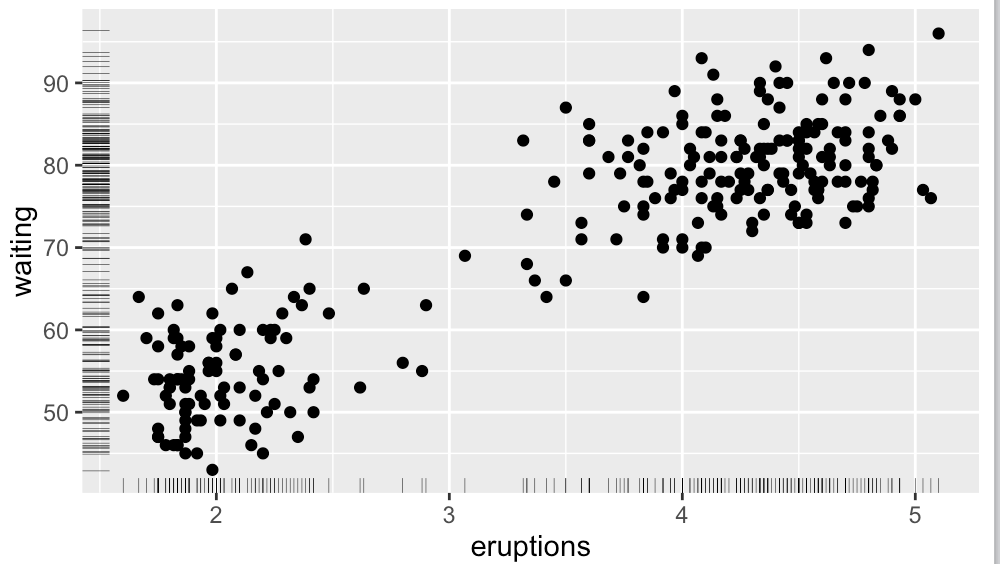
#通过边际地毯,可以快速查看每个坐标轴上数据的分布密疏情况。还可以通过向边际地毯线的位置坐标添加扰动并设定size减少线宽,从而减轻边际地毯线的重叠程度。

当x轴和y轴对应一个或两个离散型变量时,例如虽然对应数值,但是数值仅取某些离散点,可以给散点图添加扰动,使得散点分离开来。
以下使用Logistic回归拟合一个二分类的样本,可以看出V1和classn具有二分类关系,Logistic回归曲线也说明了这一点。

如果已经将类别型变量映射到散点的颜色或形状,则在添加拟合线时会分别为每一组添加一条拟合线。可以看到身高随着年龄增长而增加,到一定年龄后停止增长,且男性比女性平均身高更高。

散点图矩阵用于展示多幅散点图,pairs()函数可以创建基础的散点图矩阵,以下代码包含mpg、disp、drat和wt中任意两者的散点图。

car包的scatterplotMatrix()函数也可以生成散点图矩阵,并支持以下操作:

再来一个scatterplotMatrix()函数的使用例子,主对角线的核密度曲线改为了直方图,并且直方图以汽车气缸数为条件绘制。

gclus包中的cpairs()函数提供了一个有趣的散点图矩阵变种,支持重排矩阵中变量的位置,让相关性更高的变量更靠近主对角线,还可以对各单元格进行颜色编码来展示变量间的相关性大小。
可以发现相关性最高(0.89)的是车重(wt)和排量(disp),以及车重(wt)和每加仑英里数(mpg)。相关性最低(0.68)的是每加仑英里数(mpg)和后轴比(drat)。以下代码根据相关性大小,对散点图矩阵中的这些变量重新排序并着色。

当散点图中点数量过大时,数据点的重叠将会导致绘图效果显著变差。对于这种情况,可以使用封箱、颜色和透明度等来指定图中任意点上重叠点的数目。
smoothScatter()函数可利用核密度估计生成用颜色密度来表示点分布的散点图。

hexbin包中的hexbin()函数将二元变量的封箱放到六边形单元格中。

如果想一次性对三个定量变量的交互进行可视化,那么可以使用scatterplot3d中的scatterplot3d()函数进行绘制。

scatterplot3d()函数提供了许多选项,包括设置图形符号、轴、颜色、线条、网格线、突出显示和角度等功能。例如以下代码生成一幅突出显示效果的三维散点图,增强了纵深感并添加了连接点与水平面的垂直线
猜你喜欢
- 05-29AICoin苏州丝绸纹样数据库发布
- 05-09AICoin重磅!深圳3条地铁线路预
- 05-14AICoin【等压地理】高考地理中
- 05-25AICoin魔兽世界:不熟悉暴风城
- 05-24AICoin上博东馆常设陈列入选全
- 05-25AICoin从煤炭、石油到电力时代
- 05-13AICoin如何利用领峰贵金属APP的
- 05-12AICoin重庆至昆明高铁线路图与
- 03-01AICoin线号线号线内部抢先看